数据结构 数据结构的存储方式只有两种:数组(顺序存储)和链表(链式存储)。散列表、栈、队列、堆、树、图等等各种数据结构都是在链表或者数组上的特殊操作。Redis 提供列表、字符串、集合等等几种常用数据结构,但是对于每种数据结构,底层的存储方式都至少有两种,以便于根据存储数据的实际情况使用合适的存储方式。
数组:紧凑连续存储。
优点:1. 随机访问,查询快 2. 更节约存储空间
缺点:1. 数组扩容麻烦 2. 插入和删除操作麻烦
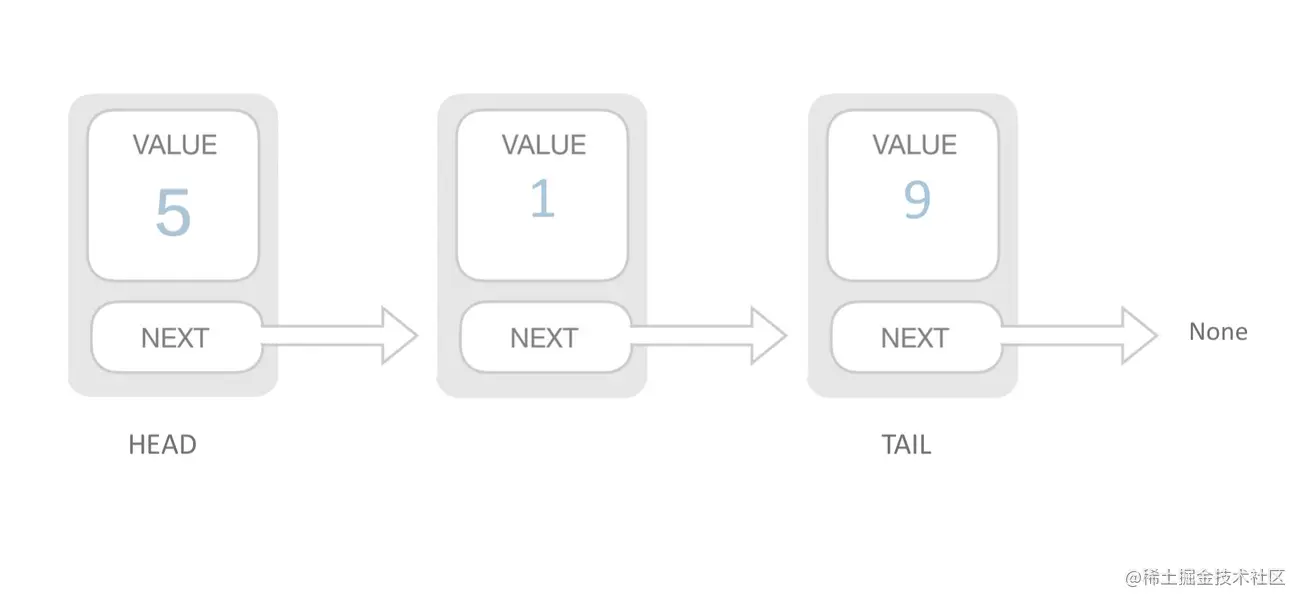
链表:元素不连续,而是靠指针指向下一个元素的位置
优点:1,数组扩容简单 2. 插入和删除操作简单
缺点:1. 不能随机访问,查询慢 2. 消耗相对更多的储存空间,要存储前驱/后驱指针。
链表 一个对象存储这个本身的值和下一个元素的地址:
function ListNode (val, next ){this .val = val === undefined ? 0 : val;this .next = next === undefined ? null : next;
链表在开发中也是经常用到的数据结构,React16 的 Fiber Node 连接起来形成的 Fiber Tree, 就是个单链表结构。
基本问题:打印、删除、反转链表
环类问题:单指针是否存在循环结构
快慢指针
哑节点(dummy)
双向链表(还有 prev 字段)
打印链表 1 2 3 4 5 6 7 8 9 function printHeadToTail (head )const array = [];while (head){push (head.val );next ;return array;
反转链表 leetcode #206
迭代:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 var reverseList = function (head ) {let prev = null ;let curr = head;while (curr !== null ) {const next = curr.next ;next = prev;return prev;
递归:
1 2 3 4 5 6 7 8 9 10 11 12 var reverseList = function (head ) {if (head == null || head.next == null ) {return head;const newHead = reverseList (head.next );next .next = head;next = null ;return newHead;
合并链表 leetcode #21
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 var mergeTwoLists = function (l1, l2 ) {let p1 = list1;let p2 = list2;const dummy = new ListNode (null );while (p1 && p2) {if (p1.val >= p2.val ) {next = p2;next ;else {next = p1;next ;next ;next = null ;if (p2) {next = p2;if (p1) {next = p1;return dummy.next ;var mergeTwoLists = function (l1, l2 ) {if (l1 === null ) {return l2;else if (l2 === null ) {return l1;else if (l1.val < l2.val ) {next = mergeTwoLists (l1.next , l2);return l1;else {next = mergeTwoLists (l1, l2.next );return l2;
快慢指针 leetcode #141
判断链表是否包含环属于经典问题了,解决方案也是用快慢指针:
每当慢指针 slow 前进一步,快指针 fast 就前进两步。
如果 fast 最终遇到空指针,说明链表中没有环;如果 fast 最终和 slow 相遇,那肯定是 fast 超过了 slow 一圈,说明链表中含有环。
1 2 3 4 5 6 7 8 9 10 11 var hasCycle = function (head ) {var slow = head, fast = head;while (fast != null && fast.next != null ) {next ;next .next ;if (slow == fast) {return true ;return false ;
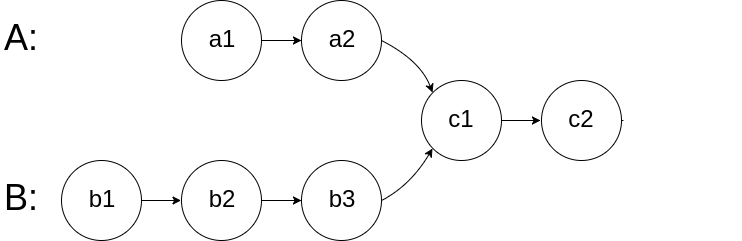
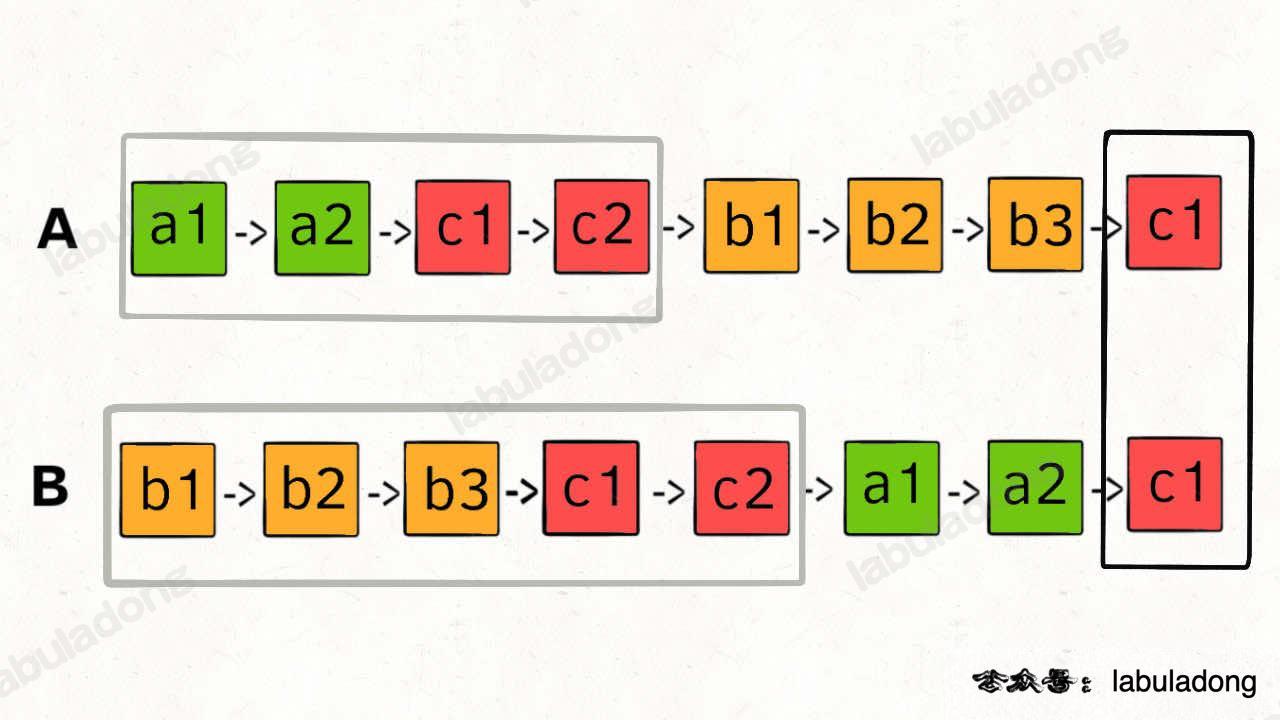
两个链表是否相交 两个链表是否相交: 拼接两个链表
leetcode #160
1 2 3 4 5 6 7 8 9 10 var getIntersectionNode = function (headA, headB ) {var p1 = headA, p2 = headB;while (p1 != p2) {if (p1 == null ) p1 = headB;else p1 = p1.next ;if (p2 == null ) p2 = headA;else p2 = p2.next ;return p1;
数组 数组是我们在开发中最常见到的数据结构了,用于按顺序存储元素的集合。但是元素可以随机存取,因为数组中的每个元素都可以通过数组索引来识别。插入和删除时要移动后续元素,还要考虑扩容问题,插入慢。
双指针技巧
快慢指针:两个指针同向而行,一快一慢
左右指针:两个指针相向而行或者相背而行(从中间向两端扩散)
N数之和
辅助数组技巧
前缀和数组:适用于原始数组不会被修改时,频繁查询某个区间的累加和 #303 #304
差分数组:适用于频繁对原始数组的某个区间元素进行增减 #370 #1094
快慢指针技巧 删除有序数组重复项
1 2 3 4 5 6 7 8 9 10 11 12 var removeDuplicates = function (nums ) {if (nums.length <= 1 ) return nums.length ;let slow = 0 , fast = 1 ;while (fast < nums.length ) {if (nums[fast] !== nums[slow]) {return slow + 1 ;
左右指针技巧 最长回文子串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 var longestPalindrome = function (s ) {const getPalindrome = (left, right ) => {while (left >= 0 && right < s.length && s[left] == s[right]) {return s.substring (left + 1 , right);let result = '' ;for (let i = 0 ; i < s.length ; i++) {const s1 = getPalindrome (i, i);const s2 = getPalindrome (i, i+1 );length > result.length ? s1 : result;length > result.length ? s2 : result;return result;
两数之和 求指针:One-Pass Hash Table
1 2 3 4 5 6 7 8 9 10 11 var twoSum = function (nums, target ) {const map = {};for (let i = 0 ; i < nums.length ; i++) {if (map[target - nums[i]] !== undefined ) {return [map[target - nums[i]], i];else {return [];
求数字:先排序,后双指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 var twoSum = function (nums, target ) {sort ((a, b ) => a - b);let p1 = 0 , p2 = nums.length - 1 ;while (p1 < p2) {let sum = nums[p1] + nums[p2];if (sum < target) {else if (sum > target) {else if (sum === target) {return [nums[p1], nums[p2]];return [];
前缀和数组 前缀和数组适用于原始数组不会被修改时,频繁查询某个区间的累加和
#303. Range Sum Query - Immutable
1 2 3 4 5 6 7 8 9 10 11 12 var NumArray = function (nums ) {this .nums = nums;this .preSum = nums.length >= 1 ? [nums[0 ]] : [];for (let i = 1 ; i < nums.length ; i++) {this .preSum [i] = this .preSum [i - 1 ] + nums[i];NumArray .prototype sumRange = function (left, right ) {const leftSum = left >= 1 ? this .preSum [left - 1 ] : 0 ;return this .preSum [right] - leftSum;
差分数组 差分数组适用于频繁对原始数组的某个区间元素进行增减
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 var Difference = function (nums ) {this .diff = [];if (nums.length > 0 ) {this .diff = new Array (nums.length );this .diff [0 ] = nums[0 ];for (var i = 1 ; i < nums.length ; i++) {this .diff [i] = nums[i] - nums[i - 1 ];Difference .prototype increment = function (i, j, val ) {this .diff [i] += val;if (j + 1 < this .diff .length ) {this .diff [j + 1 ] -= val;Difference .prototype result = function (var res = new Array (this .diff .length );0 ] = this .diff [0 ];for (var i = 1 ; i < this .diff .length ; i++) {1 ] + this .diff [i];return res;
二叉树 基础题:
前/中/后序遍历(递归/迭代)#94
层次遍历 #102
递归/遍历思路
构造
二叉搜索树
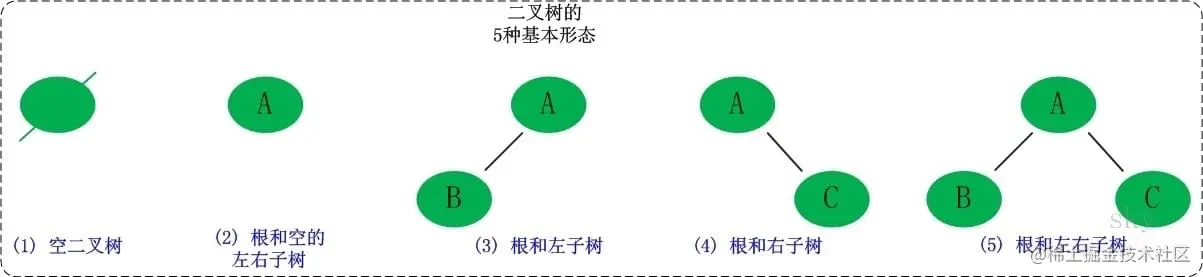
树是用来模拟具有树状结构性质的数据集合。根据它的特性可以分为非常多的种类,对于我们来讲,掌握二叉树这种结构就足够了,它也是树最简单、应用最广泛的种类。二叉树是一种典型的树树状结构。如它名字所描述的那样,二叉树是每个节点最多有两个子树的树结构,通常子树被称作“左子树”和“右子树”。
二叉树解题的思维模式分两类:
是否可以通过遍历一遍二叉树得到答案?如果可以,用一个 traverse 函数配合外部变量来实现,这叫「遍历」的思维模式。
是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案?如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值,这叫「分解问题」的思维模式。
无论使用哪种思维模式,你都需要思考:如果单独抽出一个二叉树节点,它需要做什么事情?需要在什么时候(前/中/后序位置)做?其他的节点不用你操心,递归函数会帮你在所有节点上执行相同的操作。
1.二叉树的遍历 二叉树的遍历分成三种,按照根节点的访问先后分为:
先序遍历(preorder):先访问根节点,然后访问左子树, 最后访问右子树。
中序遍历(inorder):先访问左子树,然后访问根节点, 最后访问右子树。
后序遍历(postorder):先访问左子树,然后访问右子树, 最后访问根节点。
以中序遍历为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 var inorderTraversal = function (root, array = [] ) {if (root) {inorderTraversal (root.left , array);push (root.val );inorderTraversal (root.right , array);return array;var inorderTraversal = function (root ) {let stack = [], cur = root, res = [];while (cur || stack.length ){while (cur) {push (cur);left ;pop ();push (cur.val ); right ;return res;
2.层次遍历 用了队列(queue)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 var levelOrder = function (root ) {if (!root) return [];const queue = [], res = [];push (root);while (queue.length ) {const len = queue.length ;const temp = [];for (let i = 0 ; i < len; i++) {const cur = queue.shift ();push (cur.val );if (cur.left ) queue.push (cur.left );if (cur.right ) queue.push (cur.right );push (temp);return res;
3. 递归/遍历思路 二叉树的最大深度 递归法(考虑一个节点的左右子节点该如何处理)
1 2 3 4 5 6 var maxDepth = function (root ) {if (!root) return 0 ;const left = maxDepth (root.left );const right = maxDepth (root.right );return Math .max (left, right) + 1 ;
遍历:层次遍历的变形
对称二叉树 递归法:自顶向下思考
1 2 3 4 5 6 7 8 9 10 var isSymmetric = function (root ) {return helper (root, root);var helper = function (lTree, rTree ){if (!lTree && !rTree) return true ;if (!lTree || !rTree) return false ;if (lTree.val === rTree.val && helper (lTree.left , rTree.right ) && helper (lTree.right , rTree.left )) return true ;return false ;
遍历:层次遍历的变形
4. 构造二叉树 一般是递归(即分解问题)的思路:构造整棵树 = 根节点 + 构造左子树 + 构造右子树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 var buildTree = function (preorder, inorder ) {const helpers = (preStart, preEnd, inStart, inEnd ) => {if (preStart > preEnd || inStart > inEnd) return null ;const nodeValue = preorder[preStart];const index = inorder.findIndex (item =>const leftSize = index - inStart;const node = new TreeNode (nodeValue);left = helpers (preStart + 1 , preStart + leftSize, inStart, index - 1 );right = helpers (preStart + leftSize + 1 , preEnd, index + 1 , inEnd);return node;return helpers (0 , preorder.length - 1 , 0 , inorder.length - 1 );
5.搜索二叉树 BST BST(Binary Search Tree)的特性:
对于 BST 的每一个节点 node,左子树节点的值都比 node 的值要小,右子树节点的值都比 node 的值大。
对于 BST 的每一个节点 node,它的左侧子树和右侧子树都是 BST。
从做算法题的角度来看 BST,除了它的定义,还有一个重要的性质:BST 的中序遍历结果是有序的(升序) 。
验证BST的合法性: 中序遍历是升序的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 var isValidBST = function (root ) {let stack = [];let inorder = -Infinity ;while (stack.length || root !== null ) {while (root !== null ) {push (root);left ;pop ();if (node.val <= inorder) {return false ;val ;right ;return true ;
栈和队列 1.判断括号是否有效 #20
1 2 3 4 5 6 7 8 9 10 11 12 13 14 var isValid = function (s ) {let Dict = new Map ([['(' , ')' ],['{' ,'}' ],['[' ,']' ]]);let stack = new Array ();let arr = s.split ('' );forEach (item =>let temp = stack[stack.length - 1 ];if (Dict .has (temp) && Dict .get (temp) === item){pop ()else {push (item);return !stack.length ;
2.用两个栈来实现一个队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 const stack1 = [];const stack2 = [];function push (node )push (node);function pop (if (stack2.length === 0 ){while (stack1.length >0 ){push (stack1.pop ());return stack2.pop () || null ;
哈希表 当用到哈希表时我们通常是要开辟一个额外空间来记录一些计算过的值,同时我们又要在下一次计算的过程中快速检索到它们,例如两数之和、三数之和等都利用了这种思想。
1.两数之和
1 2 3 4 5 6 7 8 9 10 var twoSum = function (nums, target ) {let map = new Map ();for (let i = 0 ; i < nums.length ; i++){if (!map.has (nums[i])){set (target - nums[i], i)else {return [map.get (nums[i]),i]
2.三数之和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 var threeSum = function (nums ) {let ans = [], len = nums.length ;if (nums == null || len < 3 ) return ans;sort ((a, b ) => a - b);for (let i = 0 ; i < len; i++) {if (nums[i] > 0 ) break ;if (i > 0 && nums[i] === nums[i-1 ]) continue ; let L = i + 1 , R = len - 1 ;while (L < R) {let sum = nums[i] + nums[L] + nums[R];if (sum === 0 ){push ([nums[i],nums[L],nums[R]])while (L<R && nums[L] == nums[L+1 ]) L++; while (L<R && nums[R] == nums[R-1 ]) R--; else if (sum < 0 ){else if (sum > 0 ){return ans;
算法 大O表示法
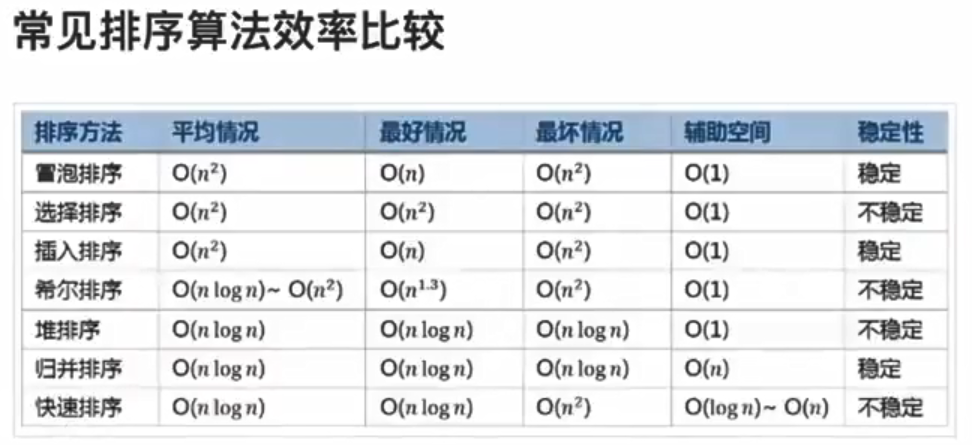
排序 1.冒泡排序 循环冒泡,把最大/最小的数冒泡到顶上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 function bubbleSort (array ) {for (let j = 0 ; j < array.length ; j++) {let complete = true ;for (let i = 0 ; i < array.length - 1 - j; i++) {if (array[i] > array[i + 1 ]) {1 ]] = [array[i + 1 ], array[i]];false ;if (complete) {break ;return array;
2.选择排序 每次排序取一个最大或最小的数字放到前面的有序序列中。
1 2 3 4 5 6 7 8 9 10 11 function selectionSort (array ) {for (let i = 0 ; i < array.length - 1 ; i++) {let minIndex = i;for (let j = i + 1 ; j < array.length ; j++) {if (array[j] < array[minIndex]) {
3.插入排序 将左侧序列看成一个有序序列,每次将一个数字插入该有序序列。插入时,从有序序列最右侧开始比较,若比较的数较大,后移一位。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 function insertSort (array ) {for (let i = 1 ; i < array.length ; i++) {let target = i;for (let j = i - 1 ; j >= 0 ; j--) {if (array[target] < array[j]) {else {break ;return array;
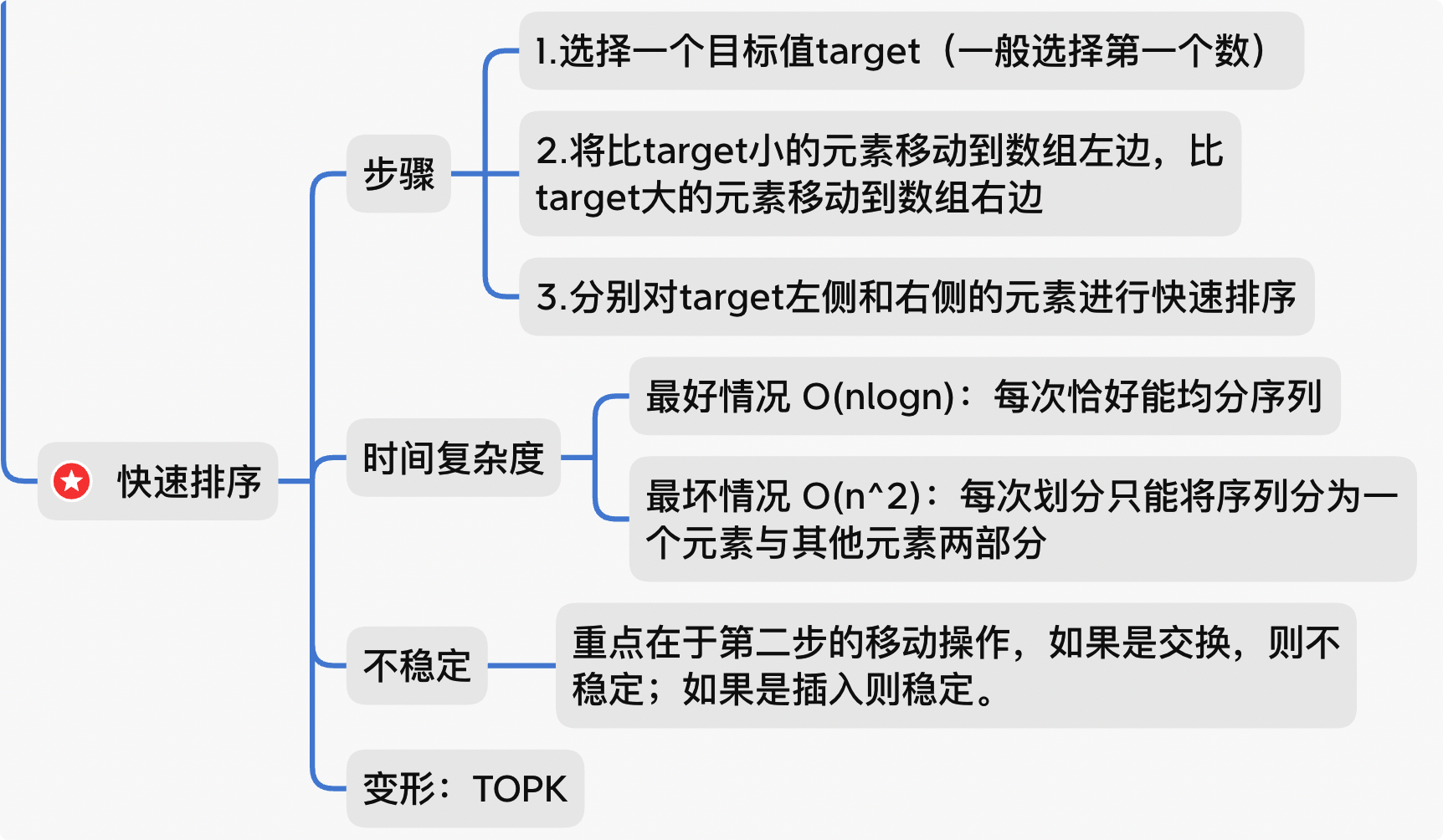
4.快速排序 选择一个目标值,比目标值小的放左边,比目标值大的放右边,目标值的位置已排好,将左右两侧再进行快排。
方法一:每次递归直接返回 left、target、right 拼接后的数组
浪费大量存储空间,写法简单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 function quickSort (array ) {if (array.length < 2 ) {return array;const target = array[0 ];const left = [];const right = [];for (let i = 1 ; i < array.length ; i++) {if (array[i] < target) {push (array[i]);else {push (array[i]);return quickSort (left).concat ([target], quickSort (right));
方法二:不需要额外存储空间,写法思路稍复杂
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 function quickSort (arr, left, right ){if (right <= left) return ;let target = arr[left]; let l = left;let r = right;while (l < r){while (l < r && target <= arr[r]){while (l < r && arr[l] <= target){quickSort (arr, left, l - 1 );quickSort (arr, l + 1 , right);return arr;
5.归并排序 将大序列二分成小序列,将小序列排序后再将排序后的小序列归并成大序列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 function mergeSort (array ) {if (array.length < 2 ) {return array;const mid = Math .floor (array.length / 2 );const front = array.slice (0 , mid);const end = array.slice (mid);return merge (mergeSort (front), mergeSort (end));function merge (front, end ) {const temp = [];while (front.length && end.length ) {if (front[0 ] < end[0 ]) {push (front.shift ());else {push (end.shift ());while (front.length ) {push (front.shift ());while (end.length ) {push (end.shift ());return temp;
6.堆排序 创建一个大顶堆,大顶堆的堆顶一定是最大的元素。交换第一个元素和最后一个元素,让剩余的元素继续调整为大顶堆。从后往前以此和第一个元素交换并重新构建,排序完成。
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。
#215 #347
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 function heapSort (array ) {creatHeap (array);console .log (array);for (let i = array.length - 1 ; i > 0 ; i--) {0 ]] = [array[0 ], array[i]];adjust (array, 0 , i);return array;function creatHeap (array ) {const len = array.length ;const start = parseInt (len / 2 ) - 1 ;for (let i = start; i >= 0 ; i--) {adjust (array, i, len);function adjust (array, target, len ) {for (let i = 2 * target + 1 ; i < len; i = 2 * i + 1 ) {if (i + 1 < len && array[i + 1 ] > array[i]) {1 ;if (array[i] > array[target]) {else {break ;
查找
二分查找
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 var search = function (nums, target ) {let left = 0 , right = nums.length - 1 ;while (left <= right){let mid = Math .floor ((left + right) /2 );if (nums[mid] > target){1 ;else if (nums[mid] < target){1 ;else {return mid;return -1 ;
递归 每当递归函数调用自身时,它都会将给定的问题拆解为子问题。递归调用继续进行,直到到子问题无需进一步递归就可以解决的地步。
斐波那契数列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 function Fibonacci (n ) {if (n < 2 ) {return n;return Fibonacci (n - 1 ) + Fibonacci (n - 2 );function fibonacci (n, memo = [] ){if (n < 2 ) return (memo[n] = n);if (!memo[n]) {fibonacci (n - 1 , memo) + fibonacci (n - 2 , memo)return memo[n];function fibonacci (n ) {const dp = [0 , 1 ];for (let i = 2 ; i <= n; i++) {1 ] + dp[i - 2 ];return dp[n];function fibonacci (n ) {if (n < 2 ) return n;let a = 0 , b = 1 ;for (let i = 2 ; i <= n; i++){const temp = b;return b;console .log (Fibonacci (5 ))
回溯算法 从解决问题每一步的所有可能选项里系统选择出一个可行的解决方案。在某一步选择一个选项后,进入下一步,然后面临新的选项。重复选择,直至达到最终状态。树状结构 表示。
选择:决定了你每个节点有哪些分支,帮助你构建出解的空间树。
约束条件:用来剪枝,剪去不满足约束条件的子树,避免无效的搜索。
目标:决定了何时捕获解,或者剪去得不到解的子树,提前回溯。
字符串 括号生成(#22):数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
1 2 输入:n = 3 "((()))" ,"(()())" ,"(())()" ,"()(())" ,"()()()" ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 var generateParenthesis = function (n ) {const res = [];const DFS = (str, left, right ) => {if (right > left || left > n || right > n) return ;if (left === n && right === n) {push (str);return ;DFS (str + '(' , left + 1 , right);DFS (str + ')' , left, right + 1 );DFS ('' , 0 , 0 );return res;
子集 全排列(#46): 给定一个 没有重复 数字的序列,返回其所有可能的全排列。
剪枝:使用used数组记录被使用过的数字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 var permute = function (nums ) {let res = [], len = nums.length ;const DFS = (path, used ) => {let depth = path.length ;if (depth === len) {push (path.slice ());return ;for (let i = 0 ; i < len; i++) {if (used[i]) continue ;push (nums[i]);true ;DFS (path, used);false ;pop ();DFS ([], new Array (len).fill (false ));return res;
子集(#78):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 const subsets = (nums ) => {const res = [];const DFS = (index, list ) => {push (list.slice ())for (let i = index; i < nums.length ; i++){push (nums[i])DFS (i + 1 , list);pop ()DFS (0 , [])return res;
二维矩阵 单词搜索(#79):给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 var exist = function (board, word ) {let r = board.length , c = board[0 ].length ;const DFS = function (i, j, k ) {if (i >= r || i < 0 || j >= c || j < 0 || board[i][j] !== word[k]) return false ;if (k === word.length - 1 ) return true ;null ; let res = DFS (i + 1 , j, k + 1 ) || DFS (i - 1 , j, k + 1 ) || DFS (i, j + 1 , k + 1 ) || DFS (i, j - 1 , k + 1 ); return res;for (let i = 0 ; i < r; i++) {for (let j = 0 ; j < c; j++) {if (DFS (i, j, 0 )) return true ;return false ;
岛屿数量(#200):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 var numIslands = function (grid ) {const r = grid.length , c = grid[0 ].length ;let counts = 0 ;const DFS = (i, j ) => {if (i < 0 || j < 0 || i >= r || j >= c || grid[i][j] === "0" ) return 1 ;'0' ;return DFS (i + 1 , j) && DFS (i, j + 1 ) && DFS (i, j - 1 ) && DFS (i - 1 , j);for (let i = 0 ; i < r; i++) {for (let j = 0 ; j < c; j++) {if (grid[i][j] === "1" ) {DFS (i, j);return counts;
岛屿最大面积(#695):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 var maxAreaOfIsland = function (grid ) {const r = grid.length , c = grid[0 ].length ;let area = 0 , temp = 0 ;const DFS = (i, j ) => {if (i < 0 || j < 0 || i >= r || j >= c || grid[i][j] === 0 ) return true ;0 ;1 ;return DFS (i, j + 1 ) && DFS (i + 1 , j) && DFS (i, j - 1 ) && DFS (i - 1 , j);for (let i = 0 ; i < r; i++) {for (let j = 0 ; j < c; j++) {0 ;if (DFS (i, j)) area = Math .max (area, temp);return area;
动态规划 动态规划的求解过程,在于找到状态转移方程 ,进行自底向上的求解。
列出正确的「状态转移方程」,才能正确地穷举
判断算法问题是否具备「最优子结构」,是否能够通过子问题的最值得到原问题的最值
是否存在「重叠子问题」,如果暴力穷举的话效率会很低,可以使用「备忘录」或者「DP table」来优化穷举过程,避免不必要的计算。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def dp (状态1 , 状态2 , ... ):for 选择 in 所有可能的选择:1 , 状态2 , ...))return result0 ][0 ][...] = base casefor 状态1 in 状态1 的所有取值:for 状态2 in 状态2 的所有取值:for ...1 ][状态2 ][...] = 求最值(选择1 ,选择2. ..)
路径问题 最小路径和:(#64)
给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
dp[i][j]是当grid[i][j]为终点时的最小路径和。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 var minPathSum = function (grid ) {let m = grid.length , n = grid[0 ].length ;let dp = new Array (m).fill (0 ).map (item =>new Array (n).fill (0 ));0 ][0 ] = grid[0 ][0 ];for (let i = 0 ; i < m; i++) {for (let j = 0 ; j < n; j++) {if (i == 0 && j != 0 ) {1 ] + grid[i][j]else if (i != 0 && j == 0 ) {1 ][j] + grid[i][j]else if (i != 0 && j != 0 ) {Math .min (dp[i][j - 1 ], dp[i - 1 ][j]) + grid[i][j]return dp[m - 1 ][n - 1 ];
股票买卖问题 买卖股票的最佳时机:
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
输入:[7,1,5,3,6,4]
假设第i天卖出股票,min是第i天之前价格最低的一天。
1 2 3 4 5 6 7 8 9 10 var maxProfit = function (prices ) {let maxProfit = 0 , minPrice = Infinity ;for (let i = 0 ; i < prices.length ; i++) {Math .min (minPrice, prices[i]);Math .max (prices[i] - minPrice, maxProfit);return maxProfit;
零钱兑换问题
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
假设你有面值为 1, 2, 5 的硬币,你想求 amount = 11 时的最少硬币数(原问题),如果你知道凑出 amount = 10, 9, 6 的最少硬币数(子问题),你只需要把子问题的答案加一(再选一枚面值为 1, 2, 5 的硬币),求个最小值,就是原问题的答案。
dp[n] = m,n是金额,m是硬币数
1 2 3 4 5 6 7 8 9 10 11 12 var coinChange = function (coins, amount ) {let dp = new Array (amount + 1 ).fill (Infinity );0 ] = 0 ;for (let i = 1 ; i < amount + 1 ; i++) {for (let j = 0 ; j < coins.length ; j++) {if (coins[j] <= i) {Math .min (dp[i], dp[i - coins[j]] + 1 );return dp[amount] > Infinity ? -1 : dp[amount];
子序列问题 最大子序和:
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
假设在i结束的子序和最大p = max{从i开始的子序和,i-1结束的子序和(p) + nums[i]}
1 2 3 4 5 6 7 8 var maxSubArray = function (nums ) {let max = nums[0 ], p = nums[0 ], len = nums.length ;for (let i = 1 ; i < len; i++) {Math .max (nums[i], p + nums[i]);Math .max (max, p)return max
最长公共子序列 给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
1 2 3 输入:text1 = "abcde" , text2 = "ace" 3 "ace" ,它的长度为 3 。
dp[i][j]的逻辑是
a[i] == a[b]: dp[i][j] = dp[i - 1][j - 1] + 1a[i] != a[b]: dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 var longestCommonSubsequence = function (text1, text2 ) {let len = 0 , len1 = text1.length , len2 = text2.length ;let dp = new Array (len1+1 ).fill (0 ).map (x =>new Array (len2+2 ).fill (0 ));for (let i = 1 ; i <= len1; i++) {for (let j = 1 ; j <= len2; j++) {if (text1[i-1 ] === text2[j-1 ]){1 ][j - 1 ] + 1 ;else {Math .max (dp[i - 1 ][j], dp[i][j - 1 ]);return dp[len1][len2];
最长公共子串
dp[i][j]的逻辑不同是a[i] != a[b],子串直接为0
a[i] == a[b]: dp[i][j] = dp[i - 1][j - 1] + 1a[i] != a[b]: 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 var findLength = function (A, B ) {let len1 = A.length , len2 = B.length , max = 0 ;let dp = new Array (len1+1 ).fill (0 ).map (x =>new Array (len2+1 ).fill (0 ));for (let i = 1 ; i <= len1; i++) {for (let j = 1 ; j <= len2; j++) {if (A[i-1 ] == B[j-1 ]) dp[i][j] = dp[i - 1 ][j - 1 ] + 1 ;else dp[i][j] = 0 ;Math .max (max, dp[i][j])
贪心算法 贪心算法:对问题求解的时候,总是做出在当前看来是最好的做法。(局部最优解)
适用贪心算法的场景:问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解。这种子问题最优解成为最优子结构
买卖股票问题 2 给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
1 2 3 4 5 6 7 8 var maxProfit = function (prices ) {let ans = 0 ;let n = prices.length ;for (let i = 1 ; i < n; ++i) {Math .max (0 , prices[i] - prices[i - 1 ]);return ans;
二进制位运算 js 中的位运算:
js 中的位运算符有下面这些,对数字进行这些操作时,系统内部都会讲 64 的浮点数转换成 32 位的整形
& 与| 或~ 非^ 异或<< 左移>> 算数右移(有符号右移) 移位的时候高位补的是其符号位,整数则补 0,负数则补 1>>> 逻辑右移(无符号右移) 右移的时候高位始终补 0
颠倒给定的 32 位无符号整数的二进制位 1 2 3 4 5 6 7 8 var reverseBits = function (n ) {let ans = 0 ;for (let i = 0 ; i < 32 ; i++) {1 ) + (n & 1 )1 ;return ans >>> 0
手写JS题目 1.防抖节流 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 function debounce (fn, delay ) {let timer = null ;return function (...args ) {clearTimeout (timer);setTimeout (() => {apply (this , args);function throttle (fn, delay ) {let timer = null ;return function (...args ) {if (!timer) {setTimeout (() => {null ;apply (this , args);
2.深拷贝 1 2 3 4 5 6 7 8 9 10 11 12 function deepClone (obj ) {let res = obj;if (typeof obj === 'object' ) {Array .isArray (obj) ? [] : {};for (let key in obj) {deepClone (obj[key]);return res;
3.手写bind、call、apply 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 Function .prototype myBind = (context ) => {if (this === Function .prototype return undefined ;let fn = this ;return function (...args ) {return fn.call (context, ...args);Function .prototype myCall = (context, ...args ) => {if (this === Function .prototype return undefined ;let fn = new Symbol ();this ;const result = context[fn](...args);delete context[fn];return result;Function .prototype myApply = function (context, args = [] ) {if (this === Function .prototype return undefined ;let fn = Symbol ();this ;const result = context[fn](...args);delete context[fn];return result;
4.函数柯里化 1 2 3 4 5 6 7 8 9 10 11 12 function curring (fn, ...args ) {if (fn.length <= args.length ) return fn (...args);return (...args2 ) => curring (fn, ...args, ...args2);function compose (...args ) {return (x ) => {let res = args.pop ()(x);return args.length ? compose (...args)(res) : res;
5.数组去重、拍平、最值、乱序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 const unique = (arr ) => Arrary .from (new Set (arr));const unique = (arr ) => arr.filter ((item, i ) => arr.indexOf (item) === i);const unique = (arr ) => {let obj = {};return arr.filter ((item, index ) => (obj[item] ? false : (obj[item] = true )));const unique = (arr ) => {for (let i = 0 ; i < arr.length ; i++) {for (let j = i + 1 ; j < arr.length ; j++) {if (arr[i] === arr[j]) {splice (j, 1 );const unique = (arr ) => {sort ((a, b ) => a - b);let res = [];if (arr.length >= 1 ) res.push (arr[0 ]);for (let i = 1 ; i < arr.length ; i++) {if (arr[i] !== arr[i - 1 ]) res.push (arr[i]);return res;function flatten (arr ) {let res = [];for (let i = 0 ; i < arr.length ; i++) {if (Array .isArray (arr[i])) res = res.concat (flatten (arr[i]));else res.push (arr[i])return res;function flatten (arr ) {return arr.reduce ((acc, cur ) => Array .isArray (cur) ? acc.concat (flatten (arr)) : acc.concat (cur), []);function flatten (arr, deep ) {let res = [];for (let i = 0 ; i < arr.length ; i++) {if (Array .isArray (arr[i]) && deep > 0 ) {concat (flatten (arr[i], deep - 1 ));else {push (arr[i]);return res;const arr = [1 , 2 , 3 , 4 ];Math .max (...arr);Math .max .apply (null , arr);reduce ((acc, cur ) => Math .max (acc, cur), -Infinity );Array .prototype reduceToMap = function (handler ) {return this .reduce ((target, current, index ) => {push (handler.call (this , current, index));return target;Array .prototype reduceToFilter = function (handler ) {return this .reduce ((target, current, index ) => {if (handler.call (this , current, index)) target.push (current);return target;function disOrder (arr ) {const len = arr.length ;for (let i = 0 ; i < len; i++){Math .floor (len * Math .random ());return arr;
6.手写ES5继承 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 function Animal (name ) {this .name = name;Animal .prototype say = function (words ) {console .log (words);function Cat (name, species ) {Animal .bind (this );this .species = species;Cat .prototype new Animal ();Cat .prototype constructor = Cat ;Cat .prototype Object .create (Animal .prototype constructor : {value : Cat ,
7.手写instanceof 1 2 3 4 5 6 7 8 9 10 function myInstanceof (object, constructor ) {let proto = object.__proto__ ;if (proto) {if (proto === constructor.prototype return true ;else return myInstanceof (proto, constructor);return false ;
8.手写Promise,手写all、race方法,手写并发控制,串行执行等 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 function myPromise (executor ) {this .value = null ;this .reason = null ;this .status = "pending" ;this .onResolvedQueue = [];this .onRejectedQueue = [];function resolve (value ) {if (self.status !== "pending" ) return ;this .value = value;this .status = "fulfilled" ;setTimeout (() => {this .onResolvedQueue .forEach (resolve =>resolve ());function reject (reason ) {if (self.status !== "pending" ) return ;this .reason = reason;this .status = "rejected" ;setTimeout (() => {this .onRejectedQueue .forEach (reject =>reject ());executor (resolve, reject);prototype then = function (onResolved, onRejected ) {if (typeof onResolved !== "function" ) onResolved = (x ) => x;if (typeof onRejected !== "function" )(x ) => {throw x;const self = this ;if (self.status === "fulfilled" ) onResolved (self.value );else if (self.status === "rejected" ) onRejected (self.reason );else if (self.status === "pending" ) {onResolvedQueue .push (() => {onResolved (self.value )});onRejectedQueue .push (() => {onRejected (self.reason )});return this ;all = function (promises ) {return new Promise ((resolve, reject ) => {const len = promises.length ;const res = new Array (len);let done = 0 ;for (let i = 0 ; i < len; i++){then ((value ) => {if (done === len) resolve (res);(reason ) => {reject (reason);return ;race = function (promises ) {return new Promise ((resolve, reject ) => {const len = promises.length ;for (let i = 0 ; i < len; i++) {then ((value ) => {resolve (value);(reason ) => {reject (reason);prototype catch = function (onRejected ) {return this .then (null , onRejected);prototype finally = function (fn ) {return this .then ((value ) => {fn ();return value;(reason ) => {fn ();return reason;function mutilRequest (promises = [], maxNum ) {const len = promises.length ;const result = new Array (len).fill (false );let count = 0 ;return new Promise ((resolve, reject ) => {while (count < maxNum) {next ();function next (let current = count++;if (current >= len) {if (!result.includes (false )) resolve (result);return ;then ((res ) => {if (current < len) next ();catch ((res ) => {if (current < len) next ();const sequence = function (arr ) {let result = [];return new Promise ((resolve, reject ) => {async function next (for (let item of arr){let temp = await item ();push (temp)resolve (result);class Scheduler {constructor (maxNum ) {this .taskList = []; this .count = 0 ; this .concurrency = concurrency;async addTask (task ) {if (this .count >= this .concurrency ) {await new Promise ((resolve ) => {this .taskList .push (resolve);this .count ++;const result = await task ();this .count --;if (this .taskList .length > 0 ) {this .taskList .shift ()?.();return result;
9.手写发布订阅模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class EventEmitter {constructor (this ._map = {};on (event, cb ){if (!this ._map [event]){this ._map [event] = [cb]else {this ._map [event] = this ._map [event].concat ([cb])emit (event, ...args ){if (this ._map (event)){this ._map (event).map (cb =>cb (...args))else {throw new Error ('没有绑定这个event' )off (event ){if (this ._map [event]){delete this ._map [event]else {throw new Error ('没有绑定这个event' )
10.手写单例模式 1 2 3 4 5 6 7 function Singleton (FunClass ) {let instance = null ;return function (...args ) {return instance == null ? (instance = new FunClass (...args)) : instance;
11.模拟new 1 2 3 4 5 6 7 8 9 10 11 function myNew (fn, ...args ) {let instance = Object .create (fn.prototype let res = fn.apply (instance, args);return typeof res === "object" ? res : instance;
附录 API String
字符操作:charAt(index),charCodeAt,fromCharCode
字符串提取:slice(start[,end]),substring(start[,end])
位置索引:indexOf(searchvalue[,start]) ,lastIndexOf
大小写转换:toLowerCase,toUpperCase
模式匹配:match(regexp),matchAll(regexp),search(searchVal),replace(searchVal,newVal),split([separator[,limit]])
其他操作:.concat(str1, str2, ..., strN),trim,startsWith(searchString)和.endsWith(searchString)
slice(start[,end])和substring(start[,end])方法提取字符串的一部分,并将其作为新字符串返回,而不修改原始字符串。未提供结束索引,则返回到字符串末尾的部分
slice的end参数可以为负数,即为从字符串末尾往前数的位置。substring的end参数不接受负数,如果传递了负数,则会将其视为0。
indexOf(searchvalue[,start])第一次出现的索引值。
split(separator)方法将字符串分割成一个有序的子串列表,将这些子串放入一个数组,并返回该数组。
match(regexp)返回一个匹配结果数组;matchAll(regexp):返回一个迭代器对象,该对象可以迭代出所有与正则表达式匹配的结果。
search()方法用于在String对象中执行正则表达式的搜索,寻找匹配项。 返回正则表达式在字符串中首次匹配的索引 ;否则,返回 -1。
1 2 3 4 5 6 7 8 9 10 11 12 const regexp = /t(e)(st(\d?))/g ;const str = "test1test2" ;match (regexp); const array = [...str.matchAll (regexp)];0 ];1 ];search (regexp); replace (regexp, 'hi~' );
Array
迭代: .map((item, index)=>{})创建一个新数组, forEach()不会。
reduce((acc, cur)=>{}, initialVal) 对数组中的每个元素按序执行一个提供的 reducer 函数,每一次运行 reducer 会将先前元素的计算结果作为参数传入,最后将其结果汇总为单个返回值。
测试:some(callbackFn)方法测试数组中是否至少有一个元素通过了由提供的函数实现的测试。every(callbackFn)方法测试一个数组内的所有元素是否都能通过指定函数的测试。返回布尔值。
过滤:filter(callbackFn)方法创建给定数组一部分的浅拷贝,其包含通过所提供函数实现的测试的所有元素。
查找:find(callbackFn)方法返回数组中满足提供的测试函数的第一个元素的值。否则返回 undefined。findIndex(callbackFn)方法返回数组中满足提供的测试函数的第一个元素的索引。若没有找到对应元素则返回 -1。
栈的使用:push(item)推入尾部,pop(item)推出尾部,shift()推出首部,unshift(item)加入首部
裁剪:slice(start[,end])方法返回一个新的数组对象,原始数组不会被改变。
排序:sort((a, b) => a - b) 升序排序;reverse反转数组,改变原数组。
其他:join(separator)拼接数组为字符串; concat(arr1, ...arrn)方法用于合并n个数组。此方法不会更改现有数组,而是返回一个新数组。
Object Object.entries()方法返回一个数组,包含给定对象自有的可枚举字符串键属性的键值对 。Object.keys()返回键的数组,Object.keys()返回值的数组。
1 2 3 4 5 6 7 8 9 10 11 12 const object1 = {a : 'somestring' ,b : 42 ,for (const [key, value] of Object .entries (object1)) {console .log (`${key} : ${value} ` );
Object.assign(target, ...sources)方法将一个或者多个源对象中所有可枚举的自有属性复制到目标对象,并返回修改后的目标对象。
1 2 3 4 5 6 7 const target = { a : 1 , b : 2 };const source = { b : 4 , c : 5 };const returnedTarget = Object .assign (target, source);console .log (target); console .log (returnedTarget === target);
Object.defineProperty(obj, prop, descriptor) 静态方法会直接在一个对象上定义一个新属性,或修改其现有属性,并返回此对象。
1 2 3 4 5 6 7 8 9 10 const object1 = {};Object .defineProperty (object1, 'property1' , {value : 42 ,writable : false ,property1 = 77 ; console .log (object1.property1 );
正则语法 正则表达式语法
普通字符:
[ABC]: 匹配方括号里所有字符[^ABC]: 匹配除了方括号里的所有字符[A-Z]: [A-Z]表示一个区间,匹配所有大写字母,[a-z]表示所有小写字母。.: 匹配除换行符之外的任何单个字符[\s\S]: 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。\w: 匹配字母、数字、下划线。等价于 [A-Za-z0-9_]\d: 匹配任意一个阿拉伯数字(0 到 9)。等价于 [0-9]
特殊字符:有特殊含义的字符。若要匹配特殊字符,必须首先使字符”转义”,即,将反斜杠字符\ 放在它们前面。
( ) 捕获分组。用圆括号 () 将所有选择项括起来,相邻的选择项之间用|分隔。
exp1(?=exp2):查找 exp2 前面的 exp1。(?<=exp2)exp1:查找 exp2 后面的 exp1。exp1(?!exp2):查找后面不是 exp2 的 exp1。(?<!exp2)exp1:查找前面不是 exp2 的 exp1
^ 匹配输入字符串的开始位置$ 匹配输入字符串的结尾位置\b 匹配一个单词边界,即字与空格间的位置。 尝试一下 »\B 非单词边界匹配。
限定符:指定正则表达式的一个给定组件必须要出现多少次才能满足匹配
+号代表前面的字符必须至少出现一次(1次或多次)*号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)?问号代表前面的字符最多只可以出现一次(0次或1次){n} 匹配确定的 n 次{n,} 匹配至少 n 次{n,m} 最少匹配 n 次且最多匹配 m 次
flags修饰符:/pattern/flags 标记也称为修饰符,正则表达式的标记用于指定额外的匹配策略。
修饰符
含义
描述
i
ignore - 不区分大小写
将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。
g
global - 全局匹配
查找所有的匹配项。
m
multi line - 多行匹配
使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。
s
特殊字符圆点 . 中包含换行符 \n
默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。